24) GPUs and CUDA#
Last time:
Coprocessors
Energy efficiency
GPU programming models
Today:
Graphics Processing Units
CUDA preview
2.1 Kernel syntax examples
2.2 Thread hierarchyMemory
Optimization Details
1. Graphics Processing Units#
Graphics Processing Units (GPUs) evolved from commercial demand for high-definition graphics.
HPC general-purpose computing with GPUs picked up after programmable shaders were added in early 2000s.
GPU vs CPU characterization#
GPU compute performance relative to CPU is not magic, rather it is based on difference in goals; GPUs were unpolluted by CPU demands for user-adaptability.
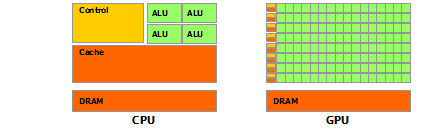
GPUs have no* branch prediction and no speculative execution. (In the early days, computational uses even needed to implement their own error correction in software!).
Longer memory access latencies from tiny cache size is meant to be hidden behind co-resident compute. The difference in mentality allowed GPUs to far surpass CPU compute efficiency.
* : recent devices use branch prediction to group divergent threads. Starting with the NVIDIA Volta architecture, Independent Thread Scheduling allows full concurrency between threads, regardless of warp.
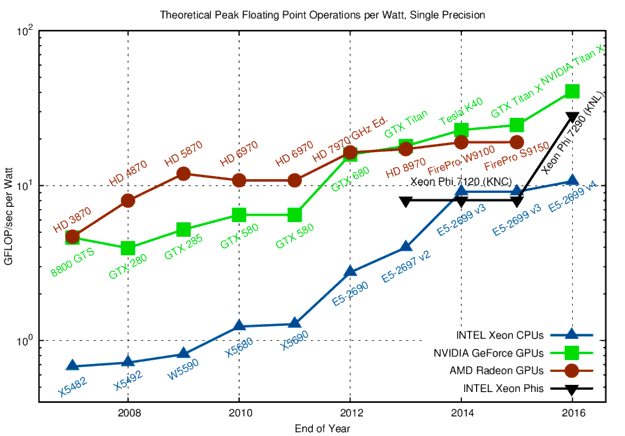
Power can dominate the cost in HPC.
Consider the Summit supercomputer example (from June 2019’s chart):
#2 GREEN500 (was #3, but #1 was decomissioned)
cost $200 million to build
13 MW to run compute+interconnect+file systems => roughly $7 million/year in raw electricity to power
(does not count facilities/infrastructure cost to actually supply this power, nor cooling or personnel)
The drawbacks: GPU efficiency needs the problem to fit well into SIMD operations and have a relatively high computation intensity.
2. CUDA preview#
Early general purpose computing GPU efforts required formulating problems in terms of graphics primatives (e.g. DirectX).
NVIDIA publicly launched CUDA in 2006, allowing programming in C (and Fortran).
Competitors: Flash forward to late 2010s - early 2020s: AMD has its own language and there are also several vendor-independent languages (dominant: OpenCL), but CUDA still dominates overall.
Nvidia maintains good documentation to ease adoption, like its programming guide.
2.1 Kernel syntax examples#
2.1.1 Hello, World!#
Our very first CUDA C example:
1#include <stdio.h>
2
3// empty function kernel() qualified with __global__
4__global__ void kernel(void)
5{
6}
7
8int main(void)
9{
10 // A call to the empty function, with additional <<<1,1>>>
11 kernel<<<1,1>>>();
12
13 printf("Hello, World! \n");
14 return 0;
15}
This simple code defines an empty function, called
kernel(), qualified with the__global__directive.In
main, we have a call to the empty function, with additional<<<1,1>>>runtime configuration parameters.
The code is compiled by the system’s standard compiler by default (nvcc).
nvcc hello_cuda.cu -o hello_cuda
This will produce the executable/object file hello_cuda, which you can simply run with
./hello_cuda
The NVIDIA tools simply feed the host compiler the source code, and everything behaves at it would be without CUDA (as it were a pure C code).
The
__global__qualifier alerts the C compiler that a function should be compiled to run on a device instead of the host.In this example
nvccgives the functionkernel()to the compiler that handles the device code, and it feedsmain()to the host compiler.In CUDA C, device function calls look very much like host function calls.
The CUDA compiler and runtime invoke device code from the host.
The angle brackets denote arguments one plans to pass to the runtime system. These are not arguments to the device code but are parameters that will influence how the device code will be launched at runtime.
Arguments to the device code itself get passed within the parenthesis, just like any other function.
2.1.2 Add two matrices#
// Add two matrices A and B of size NxN and stores the result into matrix C:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
CUDA-specific additions:
Kernels are defined with a
__global__specifier (when called by the host). (A function that executes on the device is typically called a kernel).<<<numBlocks, threadsPerBlock>>>gives the execution configuration.This means that
numBlocks * threadsPerBlockcopies of the kernel will be created and run in parallel.
Ways for threads to query their location:
threadIdx,blockIdx.
2.2 Thread hierarchy#
Threads each have their own register allocation.
They are always executed in “Single instruction, multiple threads (SIMT)”, which is an execution model used in parallel computing where single instruction, multiple data (SIMD) is combined with multithreading.
The SIMT architecture is akin to SIMD (Single Instruction, Multiple Data) vector organizations in that a single instruction controls multiple processing elements. A key difference is that SIMD vector organizations expose the SIMD width to the software, whereas SIMT instructions specify the execution and branching behavior of a single thread. In contrast with SIMD vector machines, SIMT enables programmers to write thread-level parallel code for independent, scalar threads, as well as data-parallel code for coordinated threads.
In CUDA’s SIMT architecture, at the hardware level the multiprocessor executes threads in groups of 32 called warps. If there exists a data-dependent conditional branch in the application code such that threads within a warp diverge, then the warp serially executes each branch disabling threads not on that path. The threads that remain active on the path are referred to as coalesced.
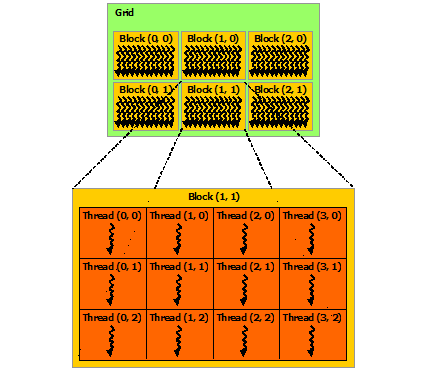
Several warps constitute a thread block. Warps are grouped in groups up to 32 (could change, but hasn’t yet). This means:
any divergence of instructions between threads within a warp causes some of the threads to no-op (relaxed recently);
product(threadsPerBlock)should be a multiple of 32 (maximum 1024) where possible.
Thread blocks each have their own shared memory allocation. All threads in a block are resident on the same processing core.
Thread layout can be up to three dimensions
can perform a lightweight synchronization within a block;
co-resident blocks can be helpful at masking latency, but this is limited by block memory and register use.
Blocks themselves are layed out on a grid of up to three dimensions (on recent compute capabilities).
They must be logically executable in parallel or any serial order
no synchronization across blocks within a kernel;
embarassingly parallel only, although caches can be reused.
Several thread blocks are assigned to a Streaming Multiprocessor (SM). Several SM constitute the whole GPU unit (which executes the whole Kernel Grid).
You can think of Streaming Multiprocessors (SMs) to be “roughly” analogous to the cores of CPUs.
The CUDA architecture is built around a scalable array of multithreaded Streaming Multiprocessors (SMs). When a CUDA program on the host CPU invokes a kernel grid, the blocks of the grid are enumerated and distributed to multiprocessors with available execution capacity. The threads of a thread block execute concurrently on one multiprocessor, and multiple thread blocks can execute concurrently on one multiprocessor.
3. Memory#
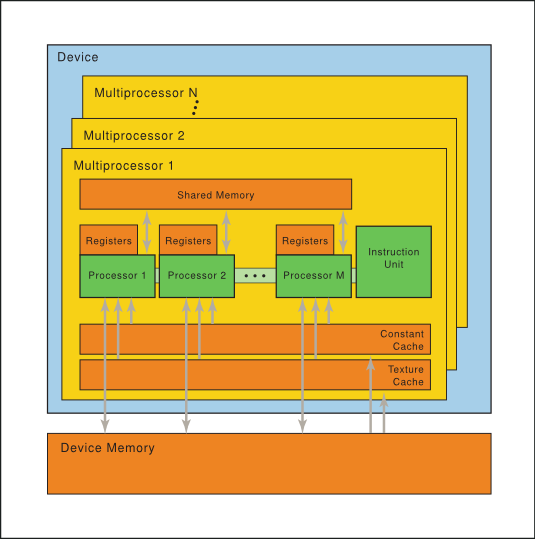
Global, constant, and texture memories persist across kernel calls, and each has its own cache per SM (L2 cache shared by SMs).
By default, host and device are assumed to maintain separate memory:
explicit device allocation and deallocation;
explicit transfer between host and device.
Alternatively, there is a “Unified Memory” configuration that automates these on an as-needed basis, pretending there is one common address space.
Each block has shared memory which tends to be fast (equivalent to a user-managed L1 cache).
Each thread has “local” memory (that is actually no more local than global memory!), which is mostly used for register spilling. (Register and shared memory usage are reported by the compiler when compiling with the
-ptxas-options=-voption.)
Global memory resides in device memory and device memory is accessed via 32-, 64-, or 128-byte memory transactions. These memory transactions must be naturally aligned: Only the 32-, 64-, or 128-byte segments of device memory that are aligned to their size (i.e., whose first address is a multiple of their size) can be read or written by memory transactions.
When a warp executes an instruction that accesses global memory, it coalesces the memory accesses of the threads within the warp into one or more of these memory transactions depending on the size of the word accessed by each thread and the distribution of the memory addresses across the threads.
Memory transfer example#
__global__ void VecAdd(float* A, float* B, float* C, int N)
{
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < N)
C[i] = A[i] + B[i];
}
int main()
{
int N = ...;
size_t size = N * sizeof(float);
// Allocate input vectors h_A and h_B in host memory
float* h_A = (float*)malloc(size);
float* h_B = (float*)malloc(size);
float* h_C = (float*)malloc(size);
// Initialize input vectors
...
// Allocate vectors in device memory
float* d_A;
cudaMalloc(&d_A, size);
float* d_B;
cudaMalloc(&d_B, size);
float* d_C;
cudaMalloc(&d_C, size);
// Copy vectors from host memory to device memory
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
// Invoke kernel
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
VecAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);
// Copy result from device memory to host memory
// h_C contains the result in host memory
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// Free device memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// Free host memory
...
}
4. Optimization Details#
Often details depend on the particular “compute capability” of the device.
Intrinsic function instructions#
similar tradeoffs to the compiler optimization flag
--ffast-math
Memory#
Hiding Memory Transfers:#
Memory transfers between host and device generally have the greatest latency. Modern capabilities can hide data transfer between host and device by giving the device other tasks to work on and having the host use asynchronous versions of the transfer functions.
This is managed through streams on the host, where CUDA calls within a stream are guaranteed to execute on the device in order, but those between streams may be out of order or overlap depending on the compute capability.
To minimize waiting with the following code, the compute capability needs to allow concurrent data transfers, concurrent kernel execution, and overlap of data transfer and kernel execution.
for (int i = 0; i < 2; ++i) {
cudaMemcpyAsync(inputDevPtr + i * size, hostPtr + i * size,
size, cudaMemcpyHostToDevice, stream[i]);
MyKernel <<<100, 512, 0, stream[i]>>>
(outputDevPtr + i * size, inputDevPtr + i * size, size);
cudaMemcpyAsync(hostPtr + i * size, outputDevPtr + i * size,
size, cudaMemcpyDeviceToHost, stream[i]);
}
Global memory access size and memory alignment:#
Example: an array of this struct would have elements that aren’t aligned if not for the __align__(16):
struct __align__(16) {
float x;
float y;
float z;
};
The
__align__(n)directive enforces that the memory for the struct begins at an address in memory that is a multiple ofnbyte (16 in this case).If the size of the struct is not a multiple of
n, then in an array of those structs, padding will be inserted to ensure each struct is properly aligned. To choose a proper value forn, you want to minimize the amount of padding required (and this will vary if you’re on a 32-bit or 64-bit machine).This usually crops up with 2D arrays, which are more efficient if width-padded to a multiple of the warp size.
For 2D array memory accesses to be fully coalesced, both the width of the thread block and the width of the array must be a multiple of the warp size.
Note: it’s a tradeoff between wasting padded memory that isn’t used and not have eccessive memory loads.
Tip
For more on this, read the dedicated section on device memory accesses in the CUDA programming guide.
Coalescence:#
Global-memory coalescence#
Global (and local*) memory requests must be coalesced—falling into the same 128-byte wide+aligned window (for all modern capabilities)—or they will require multiple instructions.
A coalesced memory transaction is one in which all of the threads in a half-warp access global memory at the same time. This is oversimplified, but coalescence occurs when consecutive threads access consecutive memory addresses.
*: the compiler will generally ensure that local memory use is coalesced
Shared-memory coalescence: Bank Distribution#
Similar, but different from global-memory coalescence. Shared memory is divided into banks (typically 32), where each bank can be accessed simultaneously.
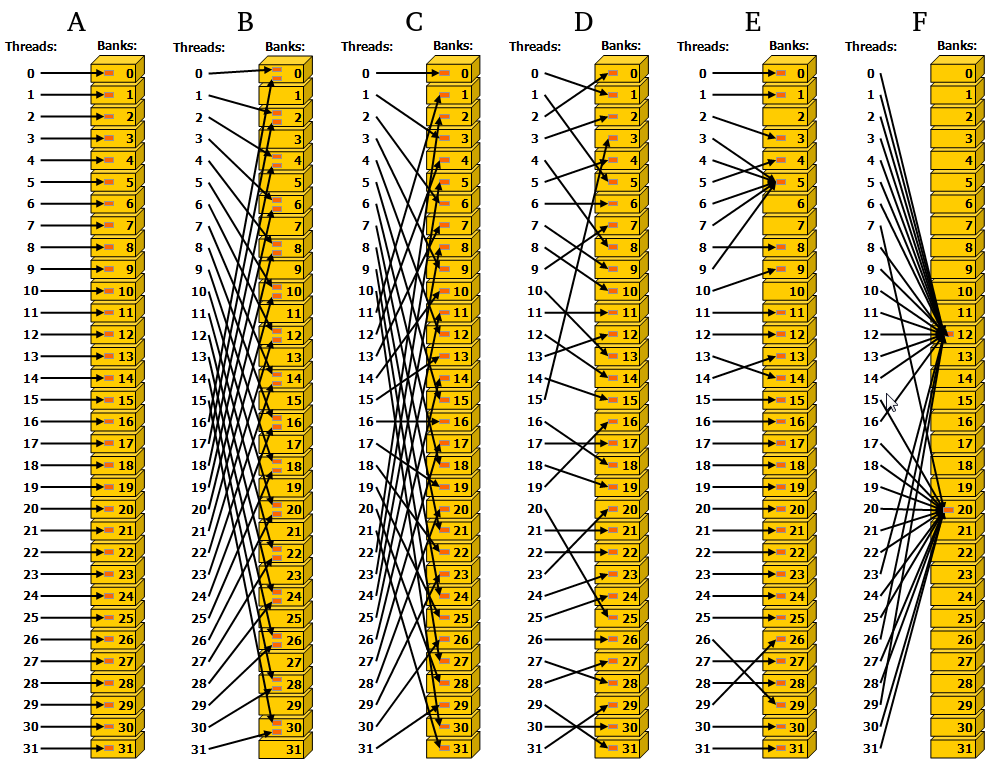
My impression is that most programmers rely on the compiler to sensibly structure bank accesses for temporary variables, but occasionally breaking into the “CUDA assembly” language PTX will yeild significant performance improvements.
The combination of coalescence and shared banks can cause an interesting interplay for certain problems. Consider:
Mx31 processor, array made of structs of 2 32-bit floats.
Coalescence would suggest padding the array to 32 wide when reading from global memory, but then once it resides in a shared memory with 32-bit strided banks, a warp of threads accessing the first of the pair of floats will cause bank conflicts of depth 2.
Shared memory would be better served by padding the array width to 31.5.
(the better solution might be to pull the struct apart…)
Texture-specific memory features:#
Optimized for 2d locality; can be faster than non-coalesced global/constant memory requests.
Ability to automatically cast 8/16-bit integers into [0,1] 32-bit floats.